Pipeforge
Personal Claude Code orchestration plugin and PostgreSQL MCP backend. Built from a personal need to coordinate work across multiple machines and parallel worktrees, then evolved into where I prototype the context-engineering patterns I apply in client work.
This is not a product. It is the infrastructure I use daily. Below: real screenshots from real runs, in execution order. Tracker IDs from a public open-source project (`POE-###`) are kept visible — they are already public on GitHub. Tracker IDs from a proprietary client project have been replaced with `[TSK-000]` placeholders.
What it does, briefly
Two orchestration patterns from different context-window eras: `/pipe` —
orchestrator clears, MCP holds state, sub-agents do the work (built to survive the compact-prone
200k era). `/deliver` — orchestrator keeps full context, dispatches from there
(viable once 1M removed compact pressure). A configurable context_window_size drives
chunk sizing independently of pattern.
Layered defence: structured state over fuzzy retrieval, source citations on KB entries, sub-agent
adversarial review, verification before completion, heavy-review (up to 5 parallel reviewer agents,
derived from the open-source pr-review-toolkit), and hook-level enforcement
(e.g. cd blocking to prevent worktree drift).
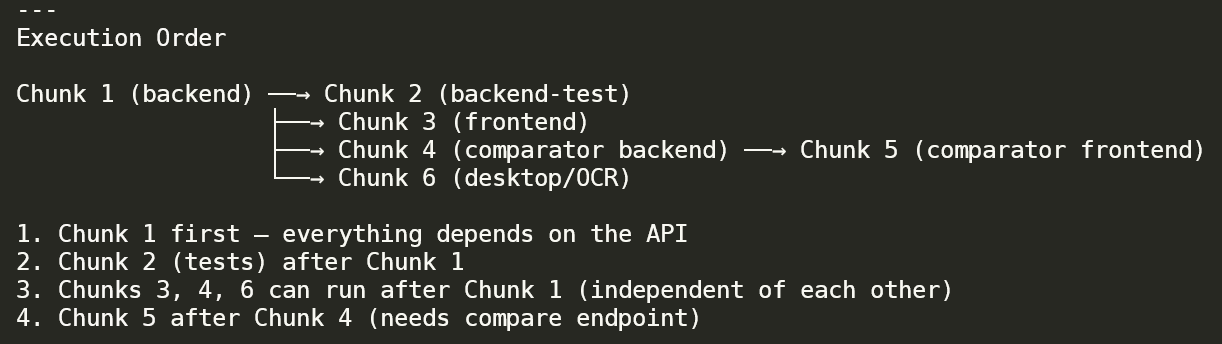
Planner output for an epic. Chunk 1 (backend) is the foundation; Chunk 2 (backend-test) waits for it; Chunks 3 / 4 / 6 (frontend, comparator backend, desktop/OCR) can run in parallel after Chunk 1; Chunk 5 (comparator frontend) waits for Chunk 4. The numbered list translates the diagram into execution rules the orchestrator follows.
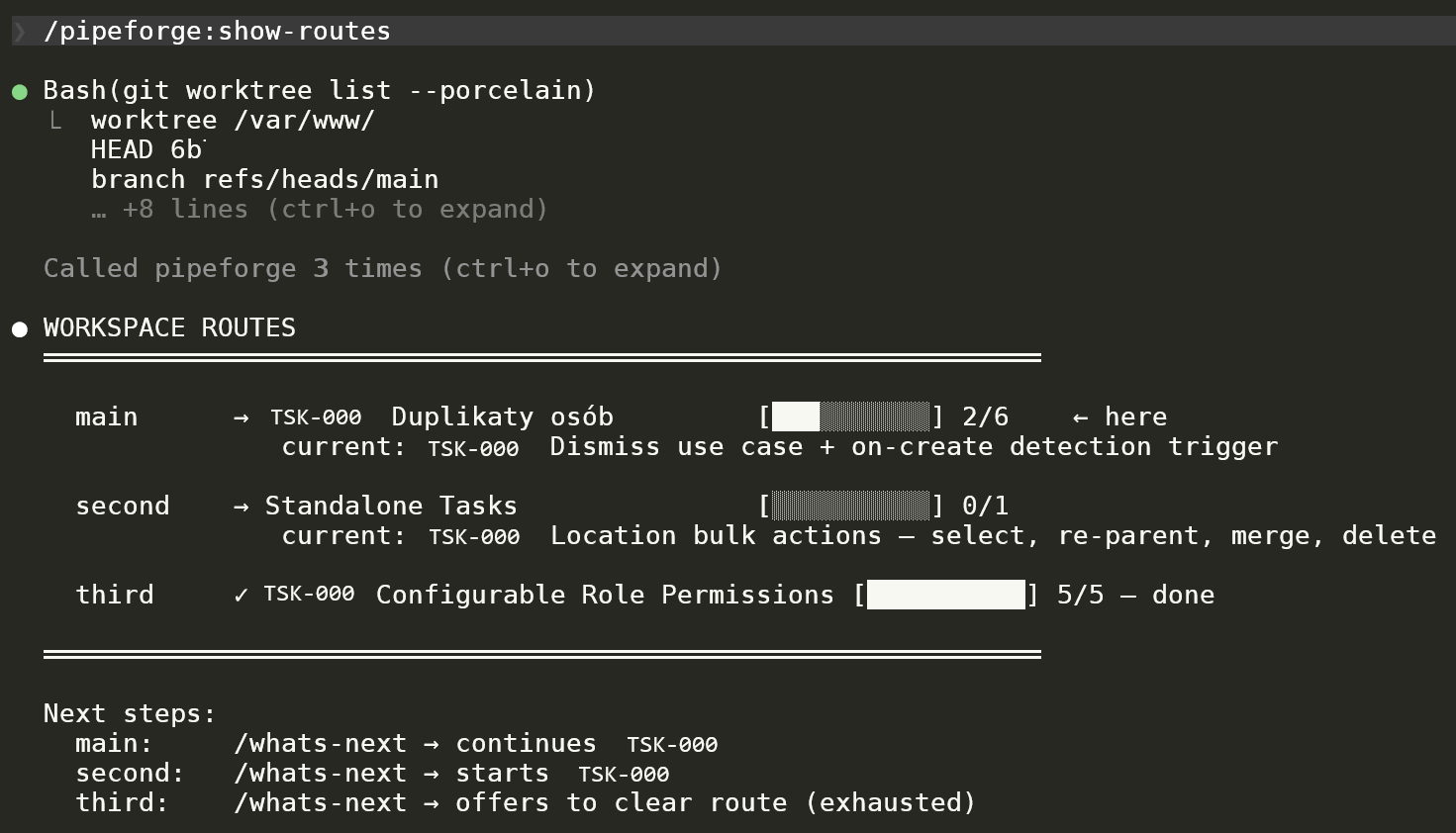
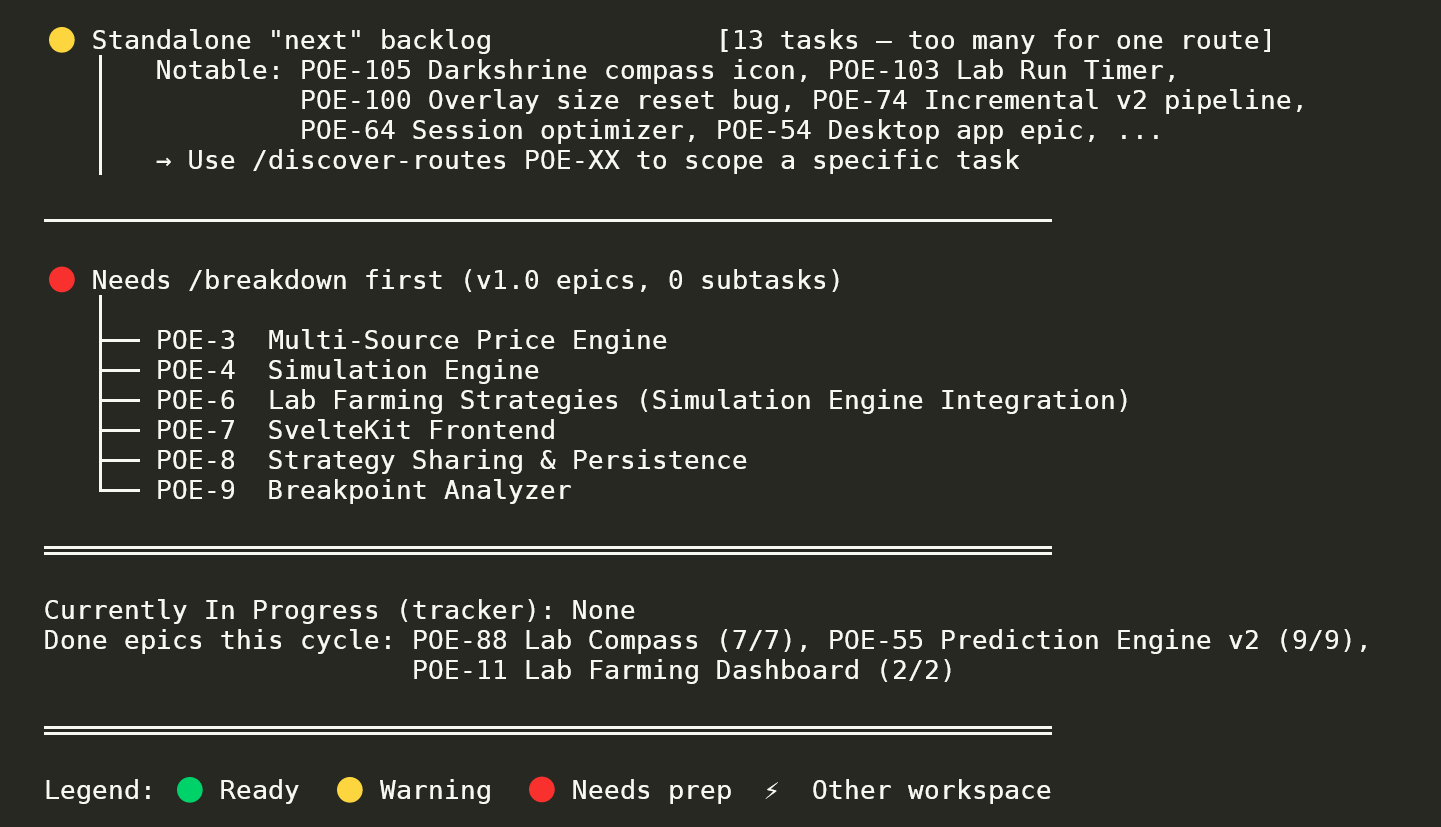
Lightweight workspace-state visualiser. Three worktrees (main / second / third), each with its active route, current in-progress task, and progress bar (2/6, 0/1, 5/5 done). Plus per-route next-step suggestions. Visual proof of the "parallel worktrees" workflow claim.
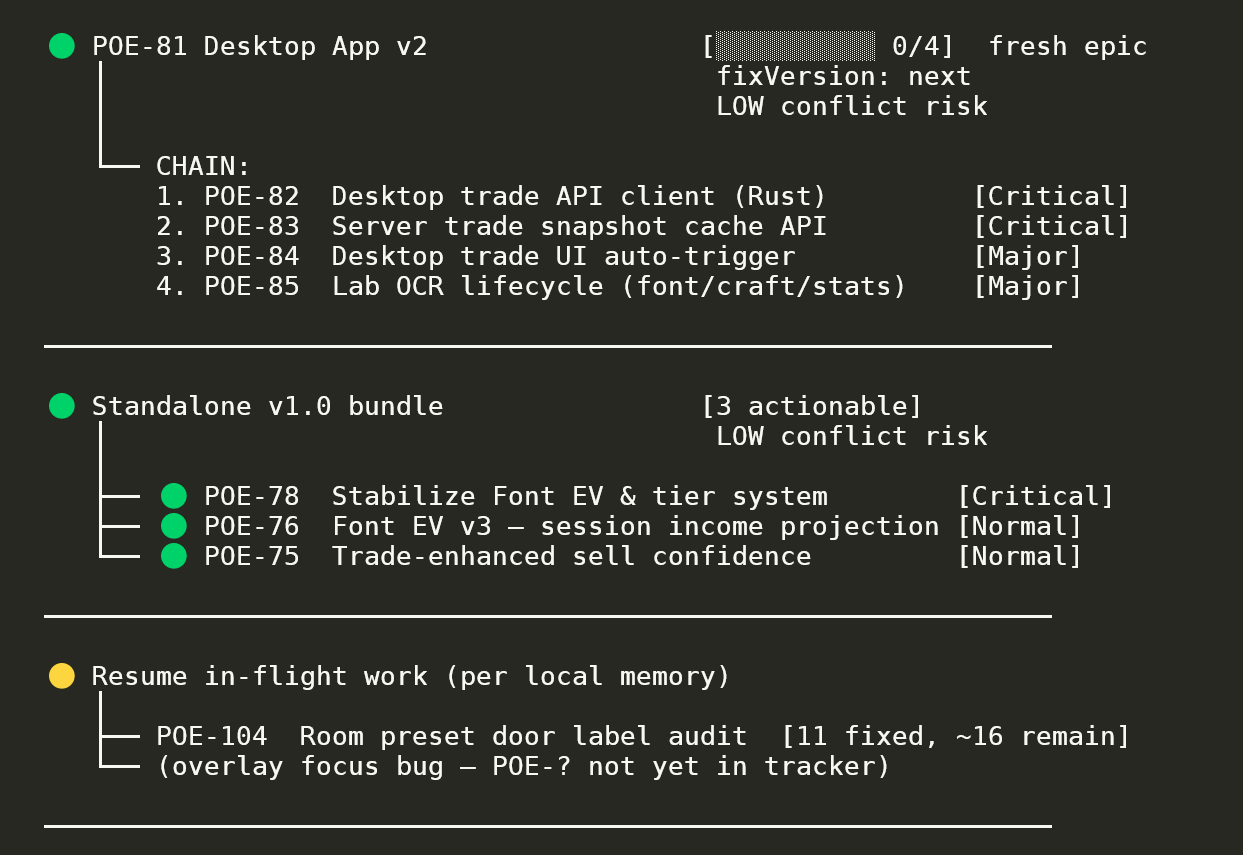
Route-discovery output across one workspace. A fresh epic (Desktop App v2, 0/4 with LOW conflict risk and 4 ordered subtasks), a 3-task actionable bundle (Standalone v1.0), and an in-flight resume option (11 fixed, ~16 remain). Status pills (●/●/●) signal readiness; conflict-risk surfaces upfront so the operator picks safely.
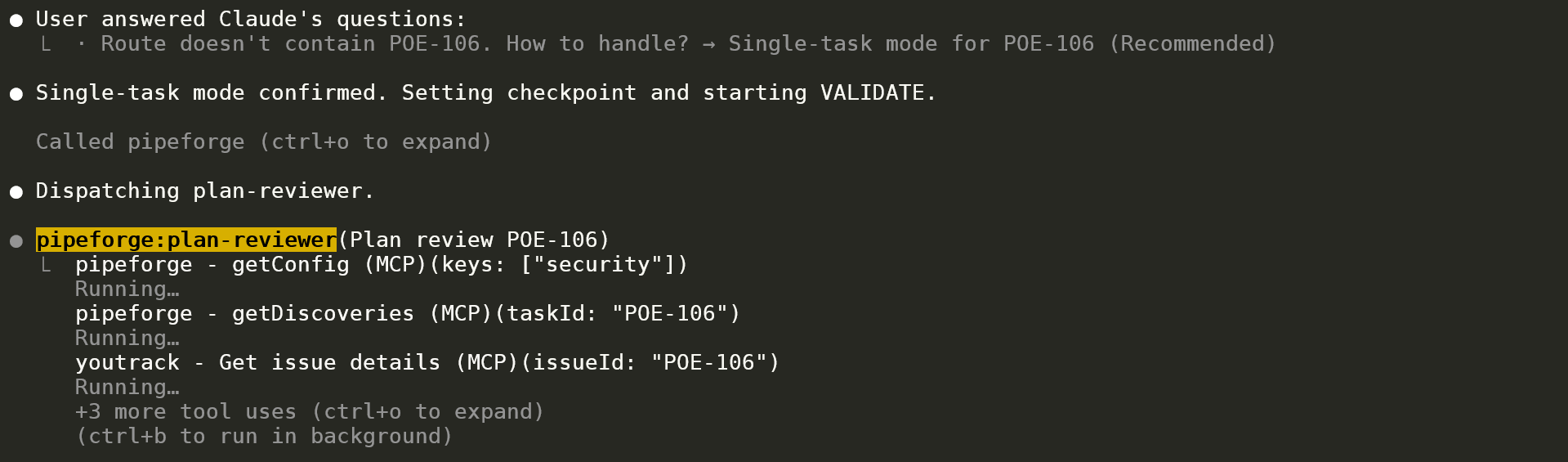
After single-task mode is confirmed, the plan-reviewer agent dispatches and immediately pulls context from MCP — Pipeforge's `getConfig` and `getDiscoveries`, plus the external tracker integration (YouTrack issue lookup). Layered context loading in action: orchestrator passes only a task ID; the sub-agent self-loads everything it needs.
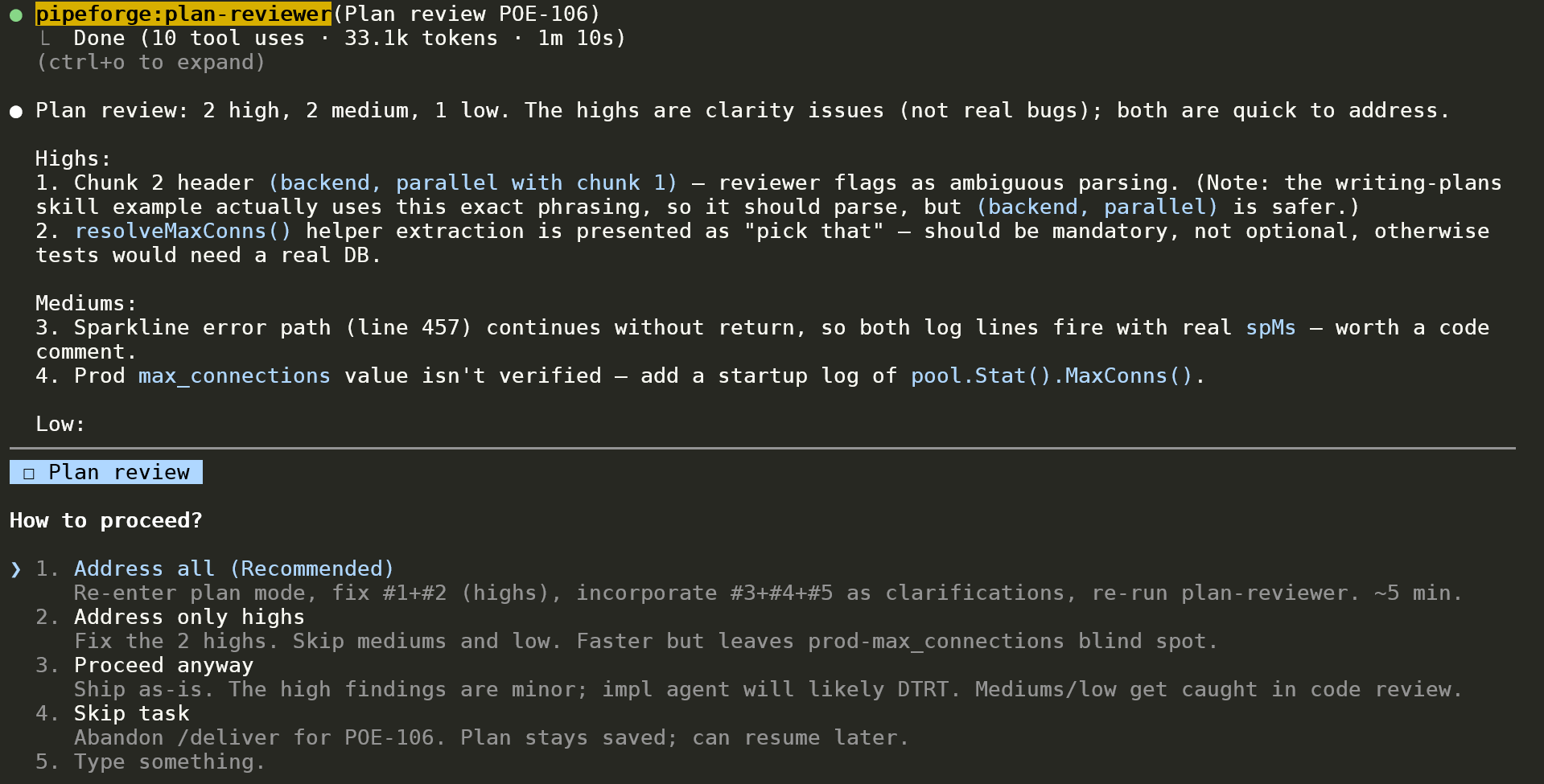
Review completed in 1m 10s (10 tool uses, 33.1k tokens). Each finding carries a one-line summary AND a concrete fix recommendation. The orchestrator then offers 4 paths: address all / highs only / proceed anyway / skip task. Implementation gate that catches design issues *before* code is written.
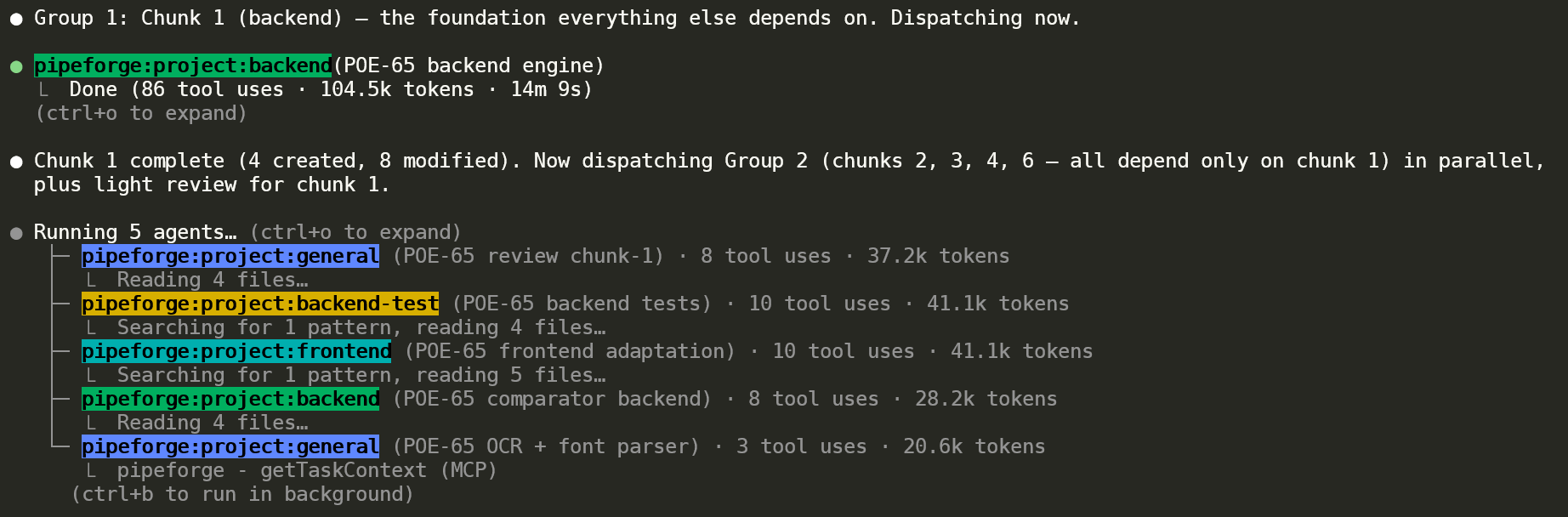
Same project as the dependency graph above, now running. Group 1 backend (POE-65 backend engine) completed — 86 tool uses, 104.5k tokens. The orchestrator then dispatches Group 2 (chunks 2 / 3 / 4 / 6, all depending on chunk 1) plus a light review for chunk 1 — 5 concurrent agents, each tagged with its specialisation (general, backend-test, frontend, backend, general). Colour-coded labels make agent type visually obvious.
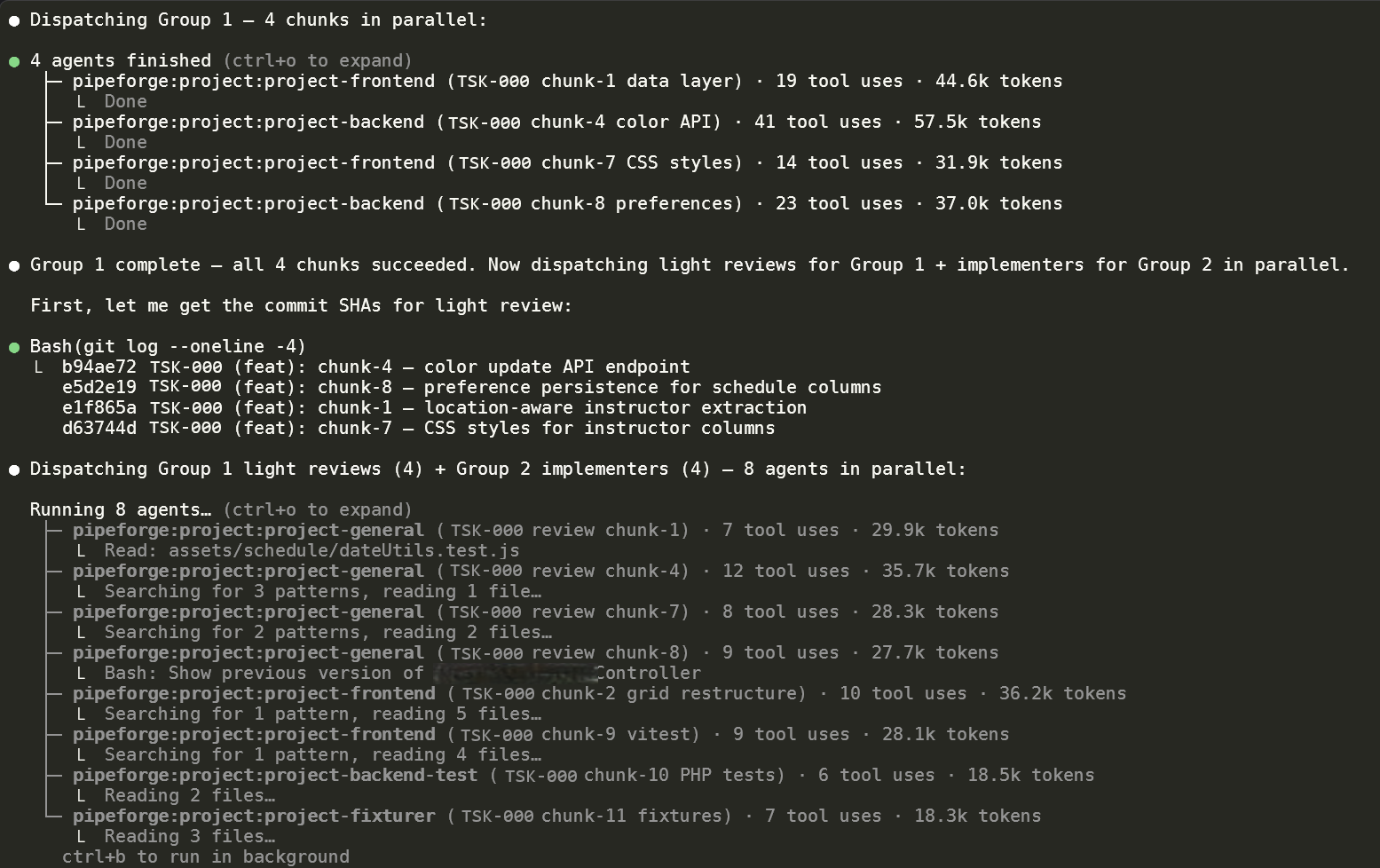
Mid-pipeline orchestration. Group 1 (4 implementer chunks: data layer, color API, CSS styles, preferences) reports per-agent token + tool-use accounting. The orchestrator immediately dispatches Group 2 implementers (4 agents) alongside light reviewers for Group 1 (4 more) — dependency-aware planning combined with parallel scheduling.
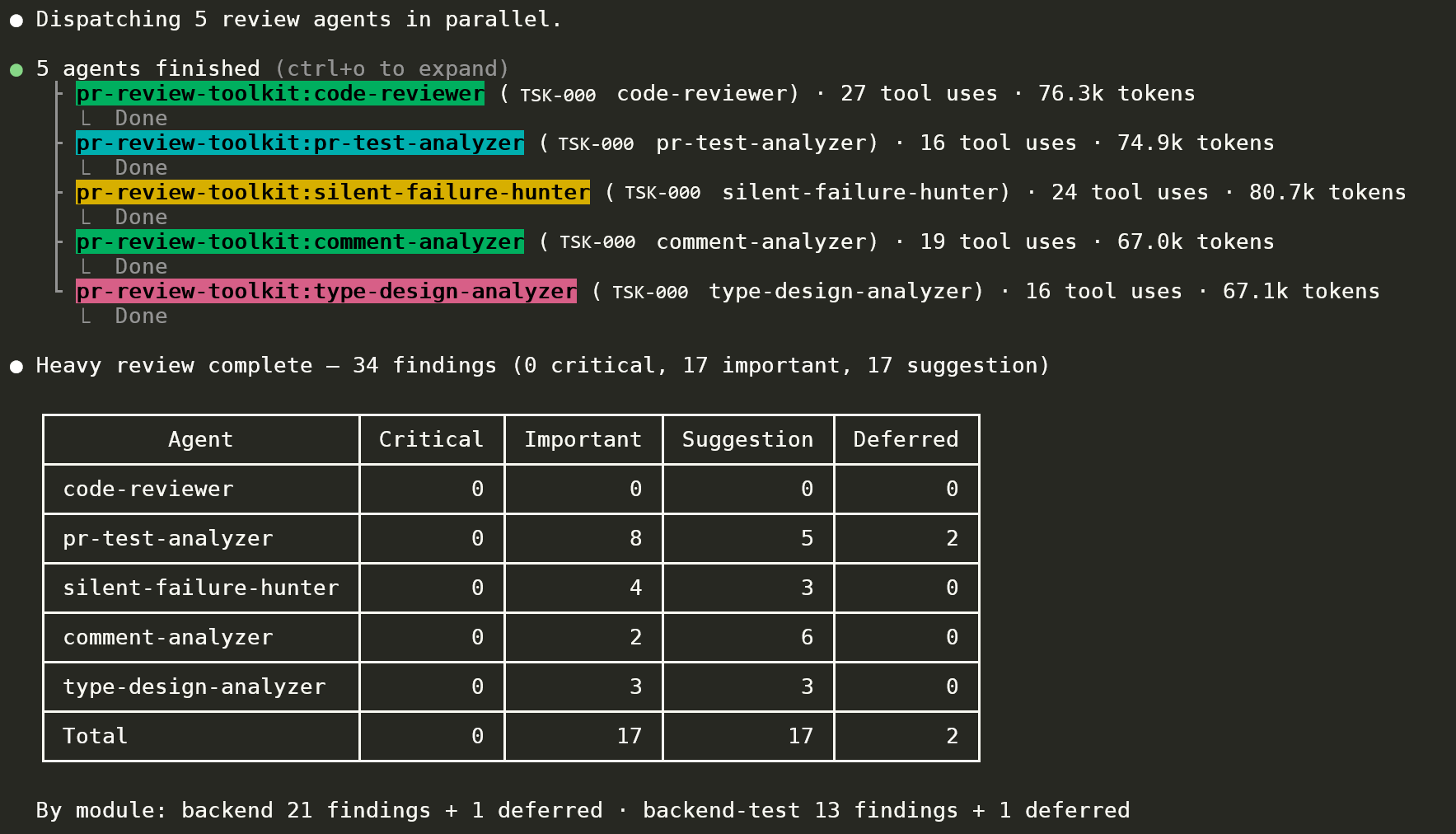
Heavy-review output. Five specialised agents finished in parallel (code-reviewer, pr-test-analyzer, silent-failure-hunter, comment-analyzer, type-design-analyzer) with token / tool-use transparency per agent. Findings classified Critical / Important / Suggestion / Deferred per agent, with a module breakdown (`backend 21+1 deferred · backend-test 13+1 deferred`). 0 Critical = merge gate clears. The pattern is derived from the open-source `pr-review-toolkit`, adapted to the Pipeforge agent model.

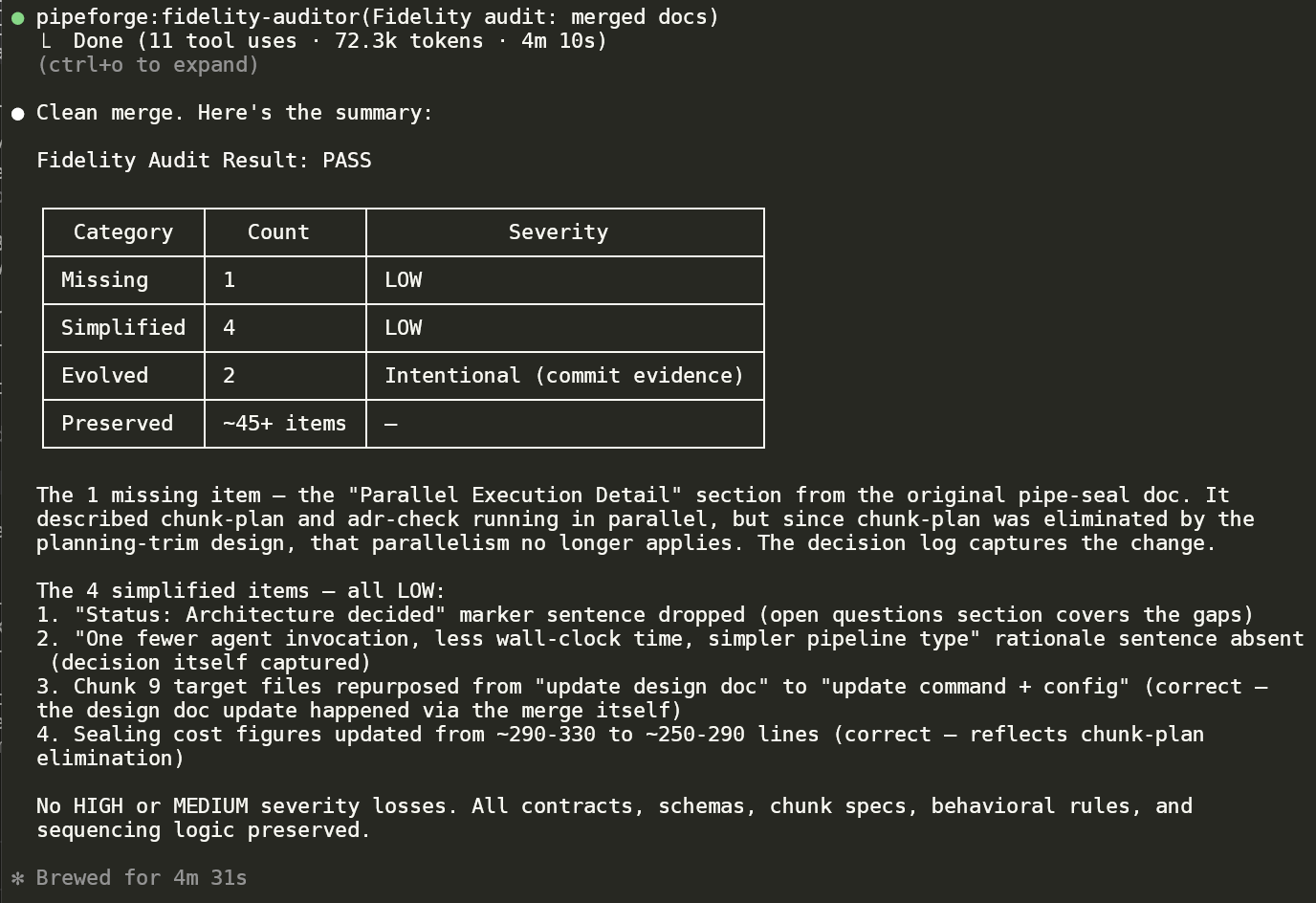
The auditor's voice on a real refactor. 17 behavioural atoms preserved across both handler moves, 0 missing. Two LOW-severity deltas surfaced with rationale: a string prefix shortening that's *more* correct given the new caller path, and a log message rename that's purely cosmetic. Calibrated, doesn't cry wolf.
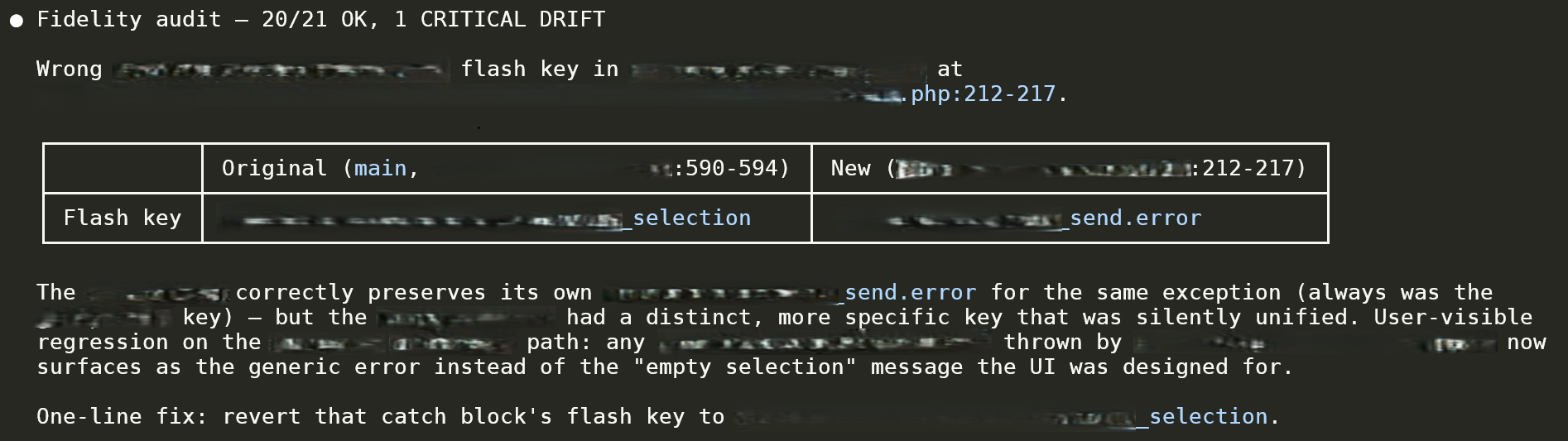
The "why this matters" example. During a refactor, an `\InvalidArgumentException` flash key changed in a way that silently merged two distinct user-facing flows into one generic error message. The auditor surfaces: original key, new key, file:line range, the exact UX consequence, and a one-line revert fix. Verdict: 20/21 OK, 1 CRITICAL DRIFT.
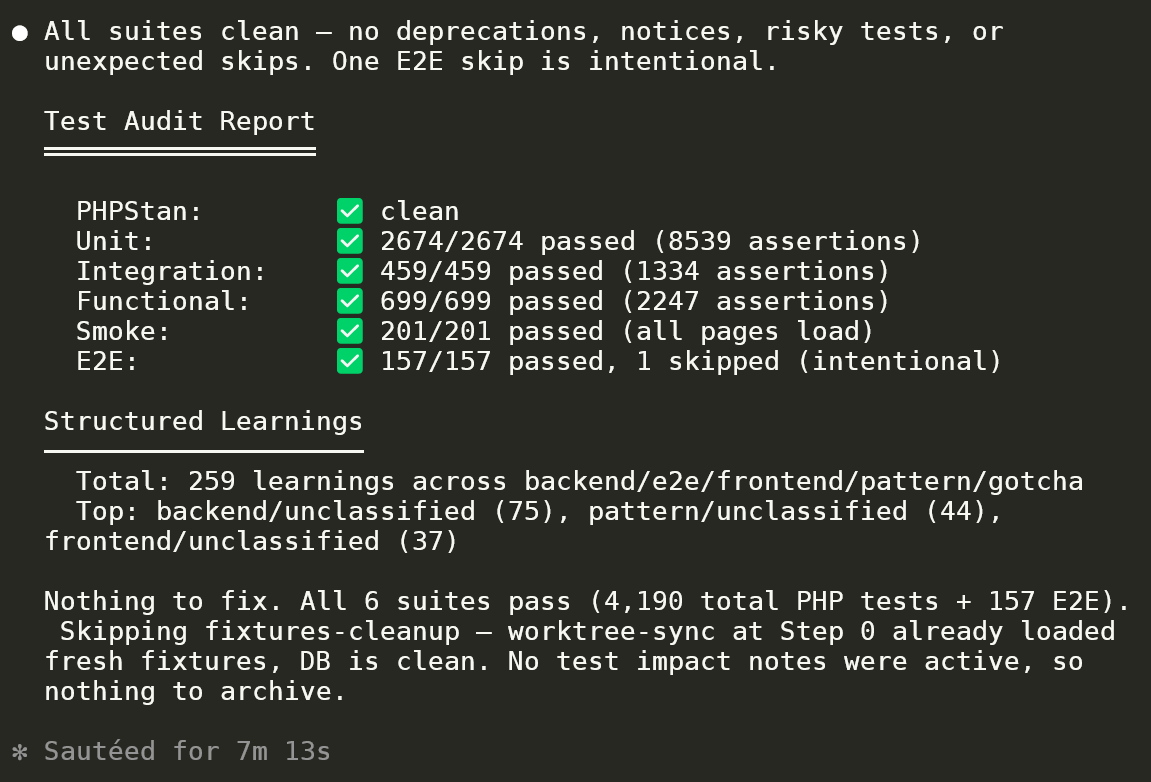
Full test-audit output. PHPStan clean, Unit 2674/2674 (8539 assertions), Integration 459/459, Functional 699/699, Smoke 201/201, E2E 157/157 (1 intentional skip). Plus 259 learnings extracted across backend / e2e / frontend / pattern / gotcha — top categories called out for the next `/integrate-agent-learnings` pass.
Two stories the screenshots back up
1 — Caught an Opus 4.7 regression with my own pipeline telemetry
After upgrading to Opus 4.7, identical pipeline shapes — same task graphs, same skills, only the model changed — ran ~2× wall-clock and ~2.3× tokens vs the Opus 4.6 baseline. Eight+ runs on real tasks ruled out variance.
Two reproducible root causes:
- Disk round-tripping of in-memory MCP results. Sub-agents materialised
MCP tool responses to the tool-results spool and looped
Read+jqover them instead of using the in-context value. Same file re-read 10+ times inside a single agent run, multiplied across every implement / heavy-review fan-out. - Literal-instruction adherence overriding session-level config. Per-session overrides ("don't post deferred items to the tracker") were acknowledged and then violated — the agent reverted to the written spec, silently, with plausible-looking output.
Shipped two revertible spec fixes — config-honoured deferred mode and DRY-extracted per-phase metrics capture — and filed the reproducible investigation upstream: anthropics/claude-code#6354.
2 — The fidelity-auditor exists because of a near-miss
During a docs migration, AI silently summarised 491 lines of behavioural specs into 122. Type-checks passed. Tests passed. The behaviour was structurally fine but operationally lossy — the kind of regression that doesn't surface until months later, in production, as "wait, I thought we did X here?"
The fidelity-auditor is the structural fix. On every move / split / extract, it classifies behavioural atoms as Missing / Simplified / Evolved / Preserved, prints severity per row, and demands explicit reasoning on every LOW. It refuses to ship a verdict it can't justify — see the two fidelity-audit panels above (a clean handler refactor with calibrated LOWs, and a real regression caught) for what that looks like in practice.
Appendix — more artefacts
Four additional screenshots covering more of the same pipeline surface. Same redaction policy as above.